Regular Expressions Getting started with Regular Expressions
Remarks
For many programmers the regex is some sort of magical sword that they throw to solve any kind of text parsing situation. But this tool is nothing magical, and even though it's great at what it does, it's not a full featured programming language (i.e. it is not Turing-complete).
What does 'regular expression' mean?
Regular expressions express a language defined by a regular grammar that can be solved by a nondeterministic finite automaton (NFA), where matching is represented by the states.
A regular grammar is the most simple grammar as expressed by the Chomsky Hierarchy.

Simply said, a regular language is visually expressed by what an NFA can express, and here's a very simple example of NFA:
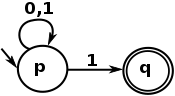
And the Regular Expression language is a textual representation of such an automaton. That last example is expressed by the following regex:
^[01]*1$
Which is matching any string beginning with 0 or 1, repeating 0 or more times, that ends with a 1. In other words, it's a regex to match odd numbers from their binary representation.
Are all regex actually a regular grammar?
Actually they are not. Many regex engines have improved and are using push-down automata, that can stack up, and pop down information as it is running. Those automata define what's called context-free grammars in Chomsky's Hierarchy. The most typical use of those in non-regular regex, is the use of a recursive pattern for parenthesis matching.
A recursive regex like the following (that matches parenthesis) is an example of such an implementation:
{((?>[^\(\)]+|(?R))*)}
(this example does not work with python's re engine, but with the regex engine, or with the PCRE engine).
Resources
For more information on the theory behind Regular Expressions, you can refer to the following courses made available by MIT:
- Automata, Computability, and Complexity
- Regular Expressions & Grammars
- Specifying Languages with Regular Expressions and Context-Free Grammars
When you're writing or debugging a complex regex, there are online tools that can help visualize regexes as automatons, like the debuggex site.
Versions
PCRE
| Version | Released |
|---|---|
| 2 | 2015-01-05 |
| 1 | 1997-06-01 |
Used by: PHP 4.2.0 (and higher), Delphi XE (and higher), Julia, Notepad++
Perl
| Version | Released |
|---|---|
| 1 | 1987-12-18 |
| 2 | 1988-06-05 |
| 3 | 1989-10-18 |
| 4 | 1991-03-21 |
| 5 | 1994-10-17 |
| 6 | 2009-07-28 |
.NET
| Version | Released |
|---|---|
| 1 | 2002-02-13 |
| 4 | 2010-04-12 |
Languages: C#
Java
| Version | Released |
|---|---|
| 4 | 2002-02-06 |
| 5 | 2004-10-04 |
| 7 | 2011-07-07 |
| SE8 | 2014-03-18 |
JavaScript
| Version | Released |
|---|---|
| 1.2 | 1997-06-11 |
| 1.8.5 | 2010-07-27 |
Python
| Version | Released |
|---|---|
| 1.4 | 1996-10-25 |
| 2.0 | 2000-10-16 |
| 3.0 | 2008-12-03 |
| 3.5.2 | 2016-06-07 |
Oniguruma
| Version | Released |
|---|---|
| Initial | 2002-02-25 |
| 5.9.6 | 2014-12-12 |
| Onigmo | 2015-01-20 |
Boost
| Version | Released |
|---|---|
| 0 | 1999-12-14 |
| 1.61.0 | 2016-05-13 |
POSIX
| Version | Released |
|---|---|
| BRE | 1997-01-01 |
| ERE | 2008-01-01 |
Languages: Bash
Character Guide
Note that some syntax elements have different behavior depending on the expression.
| Syntax | Description |
|---|---|
? | Match the preceding character or subexpression 0 or 1 times. Also used for non-capturing groups, and named capturing groups. |
* | Match the preceding character or subexpression 0 or more times. |
+ | Match the preceding character or subexpression 1 or more times. |
{n} | Match the preceding character or subexpression exactly n times. |
{min,} | Match the preceding character or subexpression min or more times. |
{,max} | Match the preceding character or subexpression max or fewer times. |
{min,max} | Match the preceding character or subexpression at least min times but no more than max times. |
- | When included between square brackets indicates to ; e.g. [3-6] matches characters 3, 4, 5, or 6. |
^ | Start of string (or start of line if the multiline /m option is specified), or negates a list of options (i.e. if within square brackets [] ) |
$ | End of string (or end of a line if the multiline /m option is specified). |
( ...) | Groups subexpressions, captures matching content in special variables (\1 , \2 , etc.) that can be used later within the same regex, for example (\w+)\s\1\s matches word repetition |
(?<name> ...) | Groups subexpressions, and captures them in a named group |
(?: ...) | Groups subexpressions without capturing |
. | Matches any character except line breaks (\n , and usually \r ). |
[ ...] | Any character between these brackets should be matched once. NB: ^ following the open bracket negates this effect. - occurring inside the brackets allows a range of values to be specified (unless it's the first or last character, in which case it just represents a regular dash). |
\ | Escapes the following character. Also used in meta sequences - regex tokens with special meaning. |
\$ | dollar (i.e. an escaped special character) |
\( | open parenthesis (i.e. an escaped special character) |
\) | close parenthesis (i.e. an escaped special character) |
\* | asterisk (i.e. an escaped special character) |
\. | dot (i.e. an escaped special character) |
\? | question mark (i.e. an escaped special character) |
\[ | left (open) square bracket (i.e. an escaped special character) |
\\ | backslash (i.e. an escaped special character) |
\] | right (close) square bracket (i.e. an escaped special character) |
\^ | caret (i.e. an escaped special character) |
\{ | left (open) curly bracket / brace (i.e. an escaped special character) |
\| | pipe (i.e. an escaped special character) |
\} | right (close) curly bracket / brace (i.e. an escaped special character) |
\+ | plus (i.e. an escaped special character) |
\A | start of a string |
\Z | end of a string |
\z | absolute of a string |
\b | word (alphanumeric sequence) boundary |
\1 ,\2 , etc. | back-references to previously matched subexpressions, grouped by () , \1 means the first match, \2 means second match etc. |
[\b] | backspace - when \b is inside a character class ( [] )matches backspace |
\B | negated \b - matches at any position between two-word characters as well as at any position between two non-word characters |
\D | non-digit |
\d | digit |
\e | escape |
\f | form feed |
\n | line feed |
\r | carriage return |
\S | non-white-space |
\s | white-space |
\t | tab |
\v | vertical tab |
\W | non-word |
\w | word (i.e. alphanumeric character) |
{ ...} | named character set |
| | or; i.e. delineates the prior and preceding options. |