Selenium WebDriver Selenium XPath
In Selenium automation, if the elements are not found by the general locators like id, class, name, etc. then XPath is used to find an element on the web page.
- XPath in Selenium is a way to navigate the structure of a webpage's HTML.
- It is a syntax for finding elements on web pages.
- It also helps find elements that are not found by locators such as ID, class, or name.
- XPath in Selenium can be used on both HTML and XML.
The basic syntax of an XPath looks like this:
//tag[@attribute='value']
- tag: It is the tag name of a particular node.
- attribute: It is the attribute name of the node.
- value: It is the value of the attribute.
The XPath has several important expressions that you definitely should know.
| Expression | Description |
|---|---|
| / | Selects from the root node. |
| // | Selects nodes in the current document that match the selection no matter where they are |
| . | Selects the current node, it is the least used XPath expressions. |
| .. | Selects the parent of the current node. |
| @ | Allows you to select attributes. |
| * | Allow you to match any element. |
XPath Types
There are two types of XPath:
- Absolute XPath
- Relative XPath
Absolute XPath
The absolute XPath is a direct way to find the element on a web page. But the drawbacks of the absolute XPath is that if there are any changes made in the path of the element then that XPath fails.
- The XPath expression is created using the selection from the root node.
- It begins with the single forward-slash(/) and traverses from the root node to the whole DOM to reach to the desired element.
Example
The absolute XPath expression of the element is shown below.
/html/body/div[1]/div[2]/div[1]/div/div/div/div[2]/div/div[1]/form/div[1]/div[1]/input
Relative XPath
The relative Xpath starts from the middle of the HTML DOM structure. It is more compact, easy to use, and less prone to broke. It doesn't need to start from the root node, which means it can search for the element anywhere on the webpage.
- It starts with a double forward-slash (//) and can search elements anywhere on the webpage, which means there is no need to write a long XPath and you can start from the middle of the HTML DOM structure.
- It is always preferred as it is not a complete path from the root element.
Example
The relative XPath expression of the element is shown below.
//*[@id='pass']
Create XPath Expressions
XPath expressions are created manually and also by using Inbuilt utilities. In most cases, the HTML file is quite big and complex, and writing the XPath of every element manually would be quite a difficult task.
So, it is always preferred to use some utility like a Chrome browser that has a built-in utility to inspect and generate the XPath for your elements.
Let's create XPath expression for the Create a Page link on the Facebook sign-in page by right-clicking on the link and select Inspect.
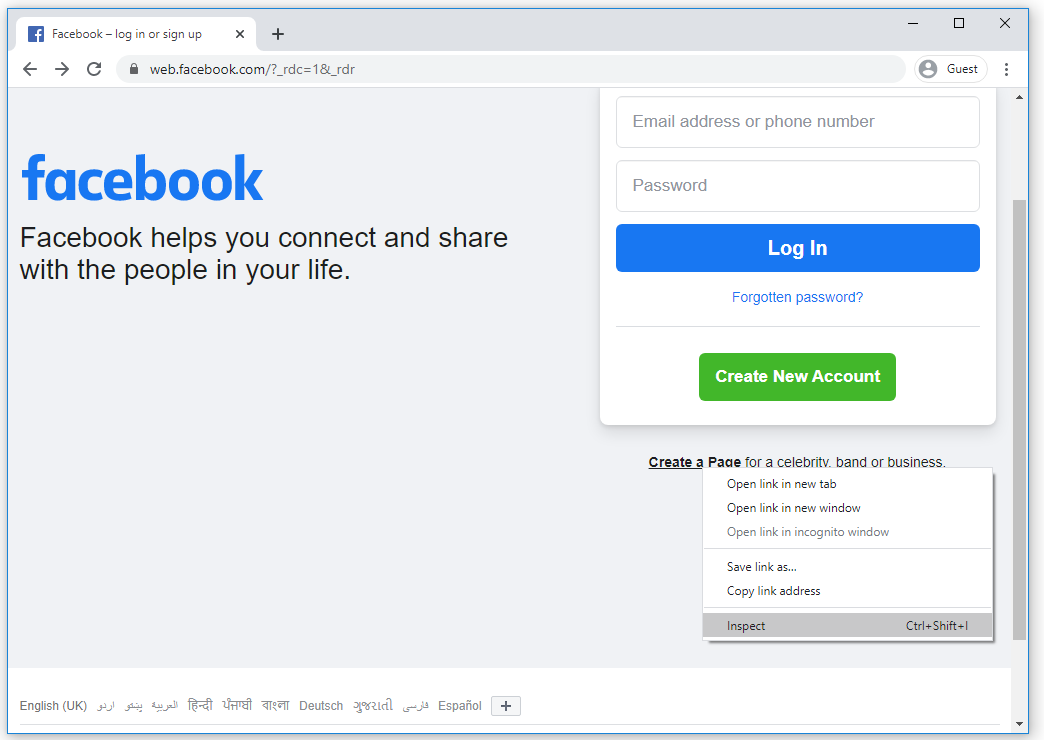
It will open the HTML DOM structure as shown below.
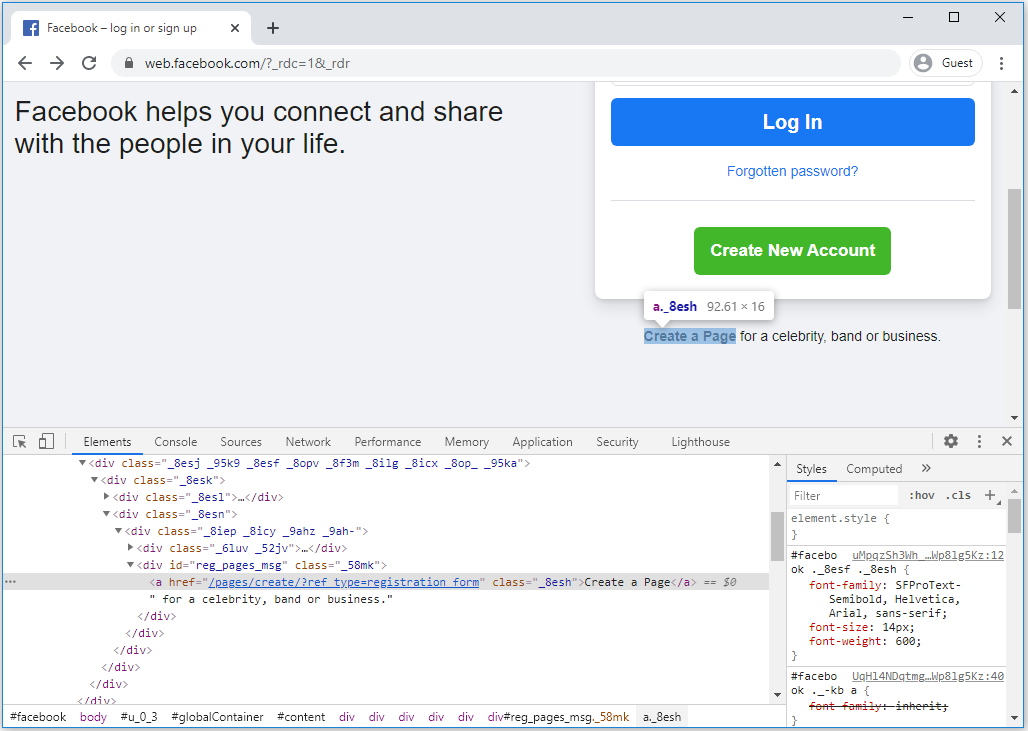
To get the Xpath of Create a Page link, right-click on HTML Structure and select Copy > Copy XPath.
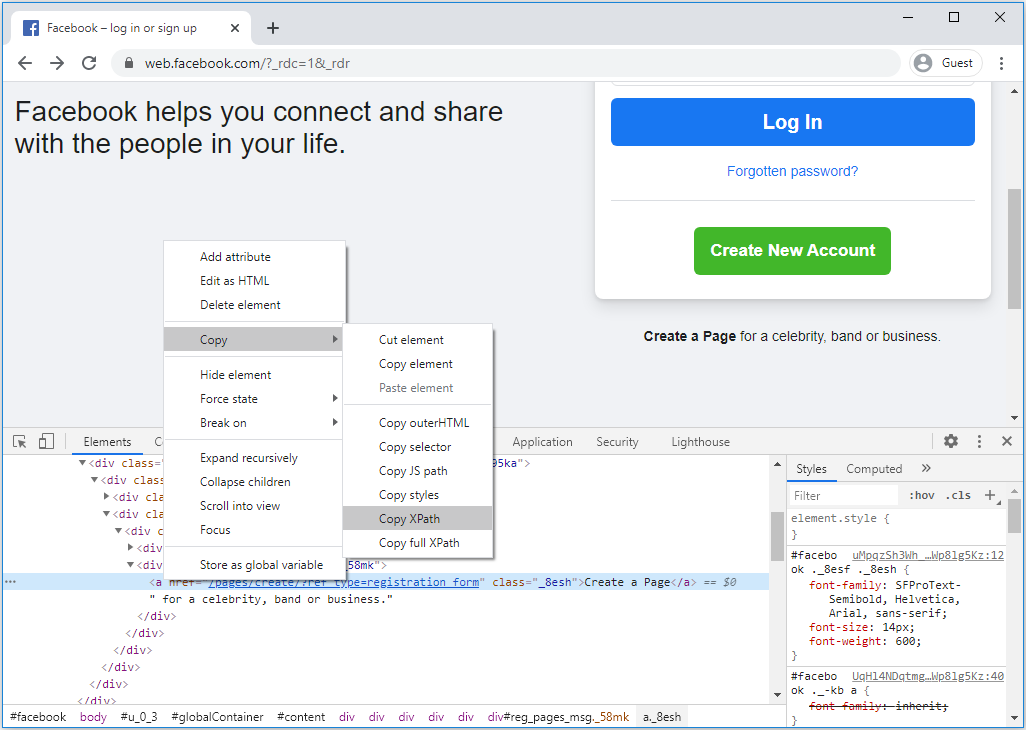
It will copy the XPath to the clipboard and when you paste it, you will see something like this:
//*[@id="reg_pages_msg"]/a